When I was a kid, I observed that most sheets of paper have a sort of “direction” inside them. It’s not possible to tell by looking, but there’s a simple experiment to show:
Rip the same sheet of paper left and right, then up and down. One of the two will have a smooth, straight, nice-looking rip, while the other will have a rough, uneven edge.
Later, as a teenager, I learned that this is called the “grain” of the paper, and that this also applies to shaving and woodworking.
I have observed that computers and programs exhibit similiar characteristics which aren’t obvious at first. Any given computer, platform, problem and program has a “grain” too. A hidden, but present underlying “optimal” (may I even call it “natural”) structure of how data flows and the factorization of the various components that would constitute it. Others seem to have observed it too.
A tryst with locality
Memory can be a funny thing, both when it comes to the self, and to computers. Take the following two pieces of C++ code for example:
|
|
Running 100 iterations on a 10x10 array filled with 0s, the first example takes 221ns and the second takes 223ns. That’s not even 1%, and maybe it can be chalked up to statistial error. But what happens when we go bigger?
| Array Size | Average 1 | Average 2 | Best 1 | Best 2 | Worst 1 | Worst 2 |
|---|---|---|---|---|---|---|
| 10x10 | 221.52ns | 223.42ns | 205ns | 211ns | 480ns | 402ns |
| 100x100 | 24646ns | 13296ns | 8163ns | 8266ns | 143007ns | 32424ns |
| 1000x1000 | 806953ns | 1.33ms | 645242ns | 951179ns | 1.5ms | 3.44ms |
| 10000x10000 | 81.3ms | 675.34ms | 70.85ms | 632.21ms | 101.65ms | 776.79ms |
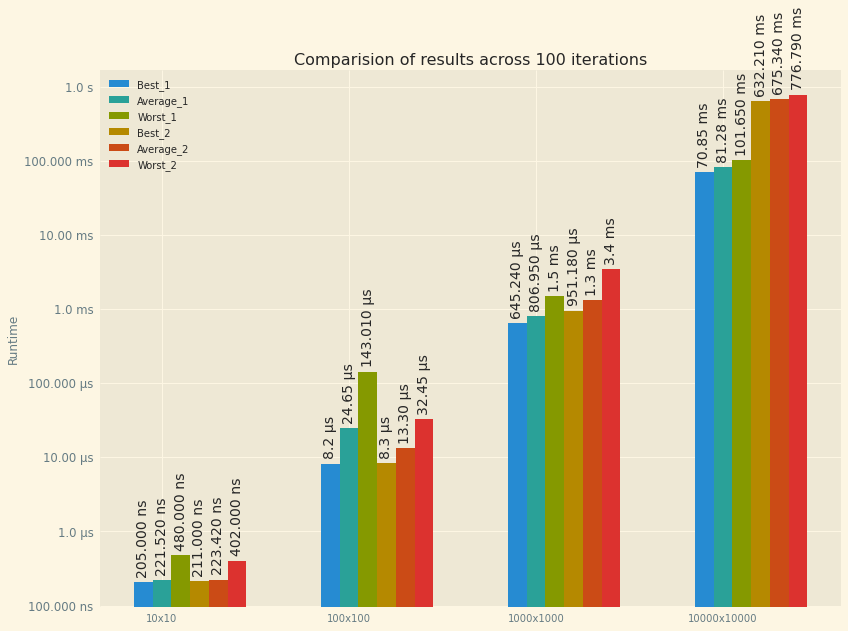
The first example performs dramatically better! But why? What is it doing different? Let’s take a closer look:
Imagine a 3 x 3 array. It might look 2D to us:
|
|
But, 2D arrays are an abstraction. Memory in computers is single dimensional, so the computer stores this as:
|
|
This drastic performance difference is because of the concept of Locality of Reference and how C++ stores your data in memory. Since C++ uses row-major ordering, accessing elements in order of rows (as in the first example) goes with the grain.
Since the elements are stored are more likely to be located nearby in memory, the processor can also “cheat” and load a contiguous chunk of memory into the cache, which allows for much faster access. However, when iterating by column (or against the grain), the processor can’t cache the columns from memory, because the columns don’t exist next to each other.
There’s more to the story than performance though.
The terrible tale of pthreads
When someone says “multithreading”, they almost always mean threading with reference to the POSIX threads model. People often complain about how difficult and error prone the usage of threads are.
However, what most people won’t tell you, is that POSIX threads are against the grain of computers. While threads can run concurrently, the underlying architecture does not directly resemble the interrupt-driven behavior of CPUs. Thread scheduling and synchronization are typically handled by the operating system, abstracting away the low-level hardware details.
The Communicating Sequential Processes (CSP) concurrency model, pioneered by Tony Hoare, focuses on communication and synchronization between concurrent processes rather than explicit thread management. In CSP, processes communicate by sending and receiving messages through channels, and synchronization is achieved through the coordination of message passing. This model aligns more closely with the interrupt-based architecture of CPUs. Go is based on this model.
When in Rome
When in Rome, one should always do as Romans do. When programming, this often extends to following the idioms of the platform and language you are working on, as well as the culture and coding guidelines of the team. That’s why, when in Python land, you follow the Zen of Python, and in Go land, you don’t use a full stack framework. This is because going against the grain of the platform makes it more difficult, and you’ll definitely know when you’re doing it.
As yacoset puts it so elegantly,
You cannot think “Fire rearward missile” and then translate it to Russian, you must think in Russian.
Consider the following program in Python that someone from a C background might write:
|
|
This goes against the grain, and is non idiomatic Python.
|
|
The idiomatic Python version utilizes the built-in sum() function with a range to directly calculate the sum of numbers from 1 to 10. It then uses an f-string to format the output and achieves the same functionality in a more concise and Pythonic way.
How about this code in Go?
|
|
In this example, we manually manage the “threads” using the sync.WaitGroup. Each URL is processed by a separate thread, and synchronization is achieved using the sync.Mutex to protect shared access to the console output.
While this approach still accomplishes concurrent processing, it deviates from the idiomatic use of goroutines and channels in Go and involves lower-level thread management.
|
|
Now, we launch a goroutine for each URL, and each goroutine fetches the content of the URL. The results are then sent back through the results channel. Finally, we collect the results and print them.
This approach, (while still not optimal) aligns with the idiomatic way of utilizing goroutines and channels for concurrent tasks in Go and is much more readable and thus maintainable in the future.
Closing thoughts
Further quoting yacoset,
There’s a thousand computer languages because there’s a thousand classes of problems we can solve with software. In the 1980s, after the Macintosh debut, a hundred DOS products were ported to the new mouse-driven platform by clubbing the Alto-inspired UI over the head and brute-forcing the keyboard-driven paradigms of PCs into the Mac’s visual atmosphere. Most of these were rejected by Apple or the market, and if they came back for a second try they came back because somebody flipped open the spiral-bound HIG and read it sincerely.
As programmers, I think we should take pride in our craft, and always try to program with the grain of the platform we are on. Many benefits await!
Read Next
I’m running an experiment for better content recommendations. These are the 3 posts that are most likely to be interesting for you:
-
To A Man With
jq, Everything Looks Like JSON
Explore how bending the rules with a tool like jq for HTML generation can spark creativity in your coding, much like programming “with the grain” harnesses the natural power of languages for better results. -
Analgesia, Pain, and the Shape of The Brain
Exploring the depths of efficiency and problem-solving, you’ll find intriguing parallels between optimizing code in programming and navigating the complexities of pain management in life. -
On "Natural Selection" and "Survival of the fittest"
Just like understanding the “grain” of programming can optimize your code, unraveling the true meaning of “natural selection” might reshape your view on how we apply Darwin’s theories in society today.